.svg "Connect Circle (animation)")
.svg "Actions Triangle (animated)")
Posted on January 25, 2019 (Last Updated: March 08, 2022)
We want to answer the key questions in our industry - helping agencies, clients and prospective customers to understand the solutions we offer.
That's why, in this latest article we are going to outline what web crawling is, how it differs from a web scrape and the benefits it can bring to e-commerce merchants and businesses.
So first things first....
What is a web crawler?
A web crawler (sometimes called a “robot"), is an Internet bot that systematically browses the web, most often for the purpose of indexing. The most common example is Google, which is crawling the web for web page information and indexing them so they can appear in Google Searches.
At Wakeupdata we’ve built something similar, however our “robot” will only crawl pages that are relevant to our clients and their businesses.
What is the difference between crawl and scrape?
Crawling is essentially what companies such as Google, Yahoo, MSN and others do, gathering any kinds of information regardless of what they are looking for.
Scraping is generally more targeted at certain websites, looking for specific information, e.g: for price comparison, so that the methodology and software are different.

How can I use the crawl from WakeupData?
Creating and maintaining a complete and well-structured set of data is crucial for product data feed optimizations - the more data you have and the better quality you have it in, the better.
There are two use cases for Wakeupdata’s crawl solution:
1. The first way to use our webcrawling solutions
is creating a completely new feed based on the data from your website.
When a merchant makes the decision to start advertising across multiple sales channels like Google Shopping, Facebook, Pricerunner etc. the first step is to have a product data feed that includes all your products and their attributes.
Some e-commerce platforms will allow you to export a data feed directly from their systems
(i.e Shopify / Magento), while in other cases you will have to create your own data feed with the help of your developers, which can become time consuming and pricey.
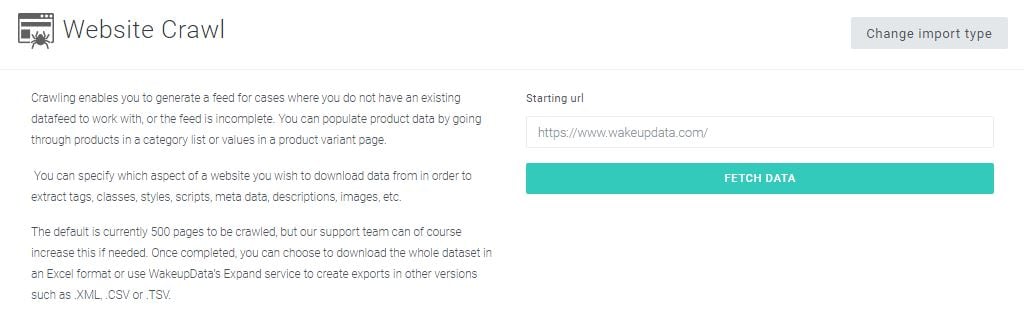
With Wakeupdata, you can crawl the data from your website quickly and have a complete set of data in no time, for a fraction of a price. We make sure you have the updated information by crawling your website daily during times when your shop is experiencing the least activity.
Also, with the extracted data we can move forward with optimizations and you have everything in one place - nice and easy.
This way you save money and focus on the core of your business. This is also an effective way for an agency to showcase an efficient solution to a client of theirs, without needing to use any developers.
2. The second way to use our webcrawling solutions
This works by enriching your product feed with missing data by scraping additional information from your website.
In this case, you have a feed that is missing certain attributes that would be great to have in order to optimise your feed- but these attributes are available on your website. With Wakeupdata you can easily extract the missing information from your product page and enrich your feed with valuable data.
This way you make sure you have a complete set of data that can be furthermore fully optimised. Wakeupdata does the job while you focus on the core of your business.
Do I need to be a coder in order to do that?
Even though understanding HTML and CSS would be a big help in the process, with just little guidance from our side anyone could become a crawling master.
At WakeupData we are on a mission to simplify otherwise complex processes of data gathering and optimisation.
Crawl & Scrape
Our intelligent web scraping and crawling solution allows you to perform the following actions:
- Got no feed? Not a problem. We can crawl it for you! You can download the whole data in Excel format or use Expand for creating exports in other versions such as .XML, .CSV or .TSV.
- Download information from websites
- Populate data from list pages
- Grab tags, styles scripts - you name it!
Crawl allows you to govern over every aspect of a website you wish to download data from:
Tags, classes, styles, scripts, meta data, descriptions, images... go after anything.
Reach out to us if you want to hear more, or visit our Crawl & Scrape page for more info about web crawling and competitor monitoring.